
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 알고리즘
- Python
- 오라클 데이터 처리방식
- 추천시스템
- 데이터 분석
- git init
- Spark jdbc parallel read
- git stash
- 의사결정나무
- Linux
- eda
- 데이터분석
- airflow 정리
- Spark 튜닝
- Decision Tree
- BFS
- 네트워크
- Oracle 논리적 저장 구조
- 앙상블
- Oracle ASSM
- enq: FB - contention
- 랜덤포레스트
- 배깅
- 리눅스 환경변수
- 통계분석
- CF
- Collaborative filtering
- SQL
- Spark Data Read
- git 기본명령어
- Today
- Total
[Alex] 데이터 장인의 블로그
데이터 분석을 위한 통계(t-test) feat. python 본문
t-test '쉽게' 기억하자
t-테스트 또는 't-검증'은 검증 통계량이 귀무가설 하에서 t-분포를 따르는 통계적 가설 검정이다. t-검증은 검증 통계량의 스케일링 항 값이 알려진 경우 검증 통계량이 정규 분포를 따르는 경우에 가장 일반적으로 적용된다.
출처: 위키백과
'데이터 분석을 위한 통계분석'의 첫번째 주제로 t-test(t-검정)에 대해 기억하기 쉽게 정리하는 시간을 가져보도록 하겠습니다!
상단의 설명대로 t-test는 t-분포(student t 분포 등 뭐시기 예전에 배웠지만 그 이야기는 무시하겠습니다) 를 활용하여 내가 세운 가설이 우연이 아닐 확률이 높은지 확인하는 과정이라 생각하시면 됩니다. 이렇게만 머릿속에 정리해두고 있는다면.. 막상 이 통계분석 방법을 써먹어야 할때 기억하기 쉽지 않겠죠!? 저는 t-test에 대해 딱 한가지만 기억하면 된다고 생각합니다.
두 집단 '평균'의 차이가 통계적으로 유의미한가?

t-검정은 '두 집단의 차이가 유의미한가'를 확인할 때 쓰입니다.
즉 A와 B라는 두가지 집단의 연속형인 데이터가 있다면 두 집단 각각의 평균의 차이가 있는지, 있다면 얼마나 통계적으로 '유의미'한지 확인하는 과정입니다. t-test를 실시하기 위해서는 등분산성, 정규성의 조건이 만족되어야 한다고 합니다.
1. 정규성
정규성의 조건은 보통 30개 데이터 이상이라면 적용된다고 여깁니다.(중심극한정리) 실제 데이터 속성에 따라 다르겠지만 보통 데이터의 Volumn이 충분히 크다면 정규성 조건을 충족한다 생각하고 t-test를 진행합니다. 보통 현재의 우리가 수집하는 데이터들의 수가 충분히 크다면 (1만개 10만개..) 정규성의 조건을 충족한다 가정하고 분석을 진행하기도 합니다.
-
사이파이 에서 제공하는 정규성검정 명령어
- 콜모고로프-스미르노프 검정(Kolmogorov-Smirnov test) : scipy.stats.ks_2samp
- 샤피로-윌크 검정(Shapiro–Wilk test) : scipy.stats.shapiro
- 앤더스-달링 검정(Anderson–Darling test) : scipy.stats.anderson
- 다고스티노 K-제곱 검정(D'Agostino's K-squared test) : scipy.stats.mstats.normaltest
-
StatsModels에서 제공하는 정규성검정 명령어
- 콜모고로프-스미르노프 검정(Kolmogorov-Smirnov test) : statsmodels.stats.diagnostic.kstest_normal
- 옴니버스 검정(Omnibus Normality test) : statsmodels.stats.stattools.omni_normtest
- 자크-베라 검정(Jarque–Bera test) : statsmodels.stats.stattools.jarque_bera
- 릴리포스 검정(Lilliefors test) : statsmodels.stats.diagnostic.lillifors
2. 등분산성
등분산성 조건을 충족하는지 확인하기 위해서는 바틀렛(bartlett), 플리그너(fligner), 레빈(levene) 검정을 주로 사용합니다. 또한 등분산성 조건을 충족하지 못하게 되더라도 t-test를 사용할 수 있습니다.
- 사이파이 에서 제공하는 등분산검정 명령어
- 바틀렛 검정(bartlett) : scipy.stats.bartlett
- 플리그너 검정(fligner) : scipy.stats.fligner
- 레빈 검정(levene) : scipy.stats.levene
한 음식점의 매출데이터를 활용하여 t-test를 진행해보겠습니다!
1. 데이터를 불러옵니다.
import pandas as pd
data = pd.read_csv("sales.csv", dtype = {'YMD' : 'object'})
data.head(10)
2. weather 데이터를 불러옵니다. (공공 데이터 api 기준)
날씨 데이터는 2020/04/25 - [데이터 분석을 위한 Python] - 데이터 분석을 위한 Python < 공공데이터 api 크롤링 > 을 참고하시면 직접 얻을 수 있습니다.
wt = pd.read_csv("weather.csv")
wt.head(10)
3. sales 데이터의 날짜를 기준으로 data를 join 하기위해 데이터 변환을 해줍니다. 2018-06-10 -> 20180610
wt.tm = wt.tm.map(lambda x : x.replace('-', ''))
4. 이후 두 데이터를 Join으로 결합합니다. ( 본 데이터 : 왼쪽 , 추가 데이터: 오른쪽 ) : LEFT JOIN
DF = data.merge(wt, how='left', left_on = 'YMD', right_on = 'tm')
DF.head(10)
5. 분석하고자 하는 데이터만 추출합니다.
data = DF.iloc[:,[0,2,7,8]]
data.head()
독립표본 t검정(Independent two-sample t-Test)
가장 많이 쓰이는 경우 입니다. A와 B 집단의 평균의 차이가 유의미한지 확인할때 독립표본 t검정을 실시합니다.
위 데이터에서 강수 여부에 따른 CNT(매출건수)의 평균 차이가 유의미한지 살펴보겠습니다.
강수O : 1 강수X : 0
data['rain_yn'] = (data.sumRn > 0).astype(int)
data
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
비가 올때의 매출건수(손님의 방문횟수)와 안올때의 매출건수를 비교하기 위해 BOX PLOT으로 나타냅니다.
sp = np.array(data.iloc[:,[1,4]])
tg1 = sp[sp[: , 1]==0,0]
tg2 = sp[sp[: , 1]==1,0]
plot_sp= [tg1, tg2]
ax = plt.boxplot(plot_sp)
plt.show()

아직까진 눈에띄는 차이가 보이지 않습니다.
정규성 검정을 위해 각각 데이터의 개수를 체크합니다. (N>30)
data.groupby('rain_yn').count()
아래 검정들을 수행해보니 등분산 조건을 충족하는 것으로 보여집니다.
# 등분산 검정
print(stats.levene(tg1, tg2))
print(stats.fligner(tg1, tg2))
print(stats.bartlett(tg1, tg2))
이제 T-TEST를 수행해줍니다. (등분산 조건 충족)
stats.ttest_ind(tg1, tg2, equal_var=True)
해석:
정규성, 등분산성 조건은 충족했습니다.
하지만 T-검정을 수행해보니 유의확률이 0.84로 유의수준(0.05)이상이므로 귀무가설이 기각되지 못하였으므로 A,B (강수여부)에 따른 매출건수의 평균의 차이는 없다고 보여집니다.
대응표본 t검정(Paired two-sample t-Test)
두 집단의 표본이 1대1 대응하는 경우, 사용됩니다. 즉 한국초등학교 1학년 애들이 4월에 중간고사를 한번 치르고 이후 전부 EBS 인터넷 강의로 대체한 이후, 기말고사를 치르게 되면 A(중간고사)점수 = B(기말고사)점수 1대1로 대응될 것입니다. 이런 경우의 평균의 차이가 유의미한지 (성적이 올랐는지, 떨어졌는지) 대응표본 T검정으로 살펴볼 수 있습니다.
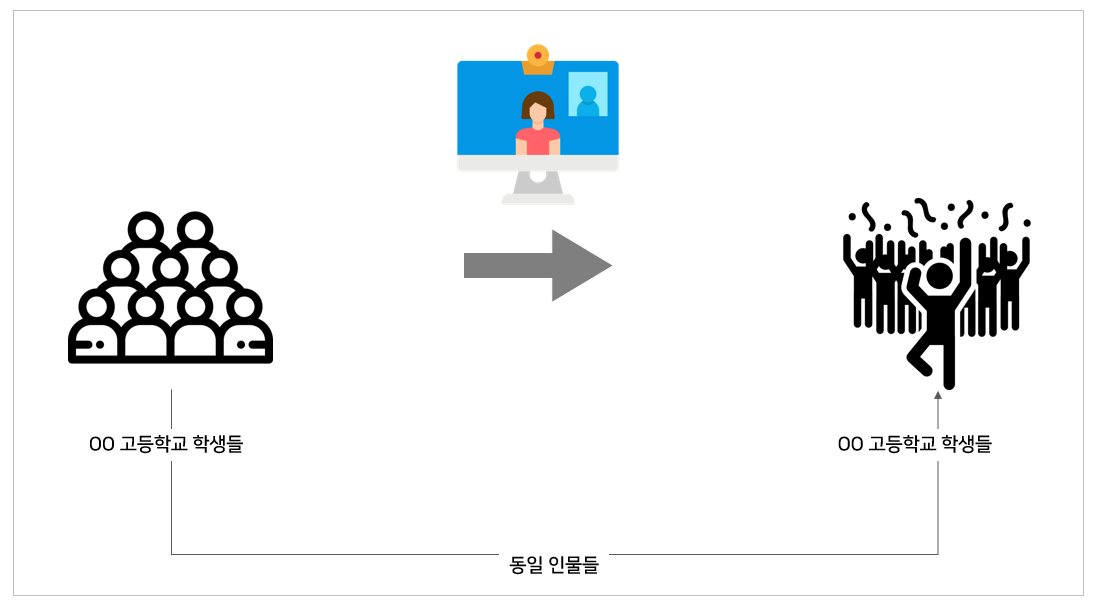
단일표본 t검정(One-sample t-Test)
내가 기댓값(ex. 모수의 평균)을 아는 경우 집단의 평균의 차이와 비교합니다.
한국고등학교 1학년 8반 애들의 수학 시험 점수 평균이 86.3점이라고 가정해봅시다. 내가 한국고등학교 1학년 수학시험 점수의 평균이 89점이라고 아는 상황이라면 이 점수를 활용하여 모집단의 평균과 차이가 있는지 확인해볼 수 있습니다.
이런 경우 단일표본 T검정을 활용합니다.
'Statistic' 카테고리의 다른 글
| 데이터 분석을 위한 통계(PCA - 주성분분석) feat.python (0) | 2020.06.14 |
|---|---|
| 데이터 분석을 위한 통계(카이스퀘어 검정) feat. python (2) | 2020.05.26 |
| 데이터 분석을 위한 통계(ANOVA) feat. python (0) | 2020.05.10 |


