
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터분석
- eda
- 배깅
- 알고리즘
- git 기본명령어
- Oracle 논리적 저장 구조
- 네트워크
- Decision Tree
- 추천시스템
- 통계분석
- CF
- Collaborative filtering
- SQL
- Spark jdbc parallel read
- 데이터 분석
- airflow 정리
- git stash
- Python
- enq: FB - contention
- BFS
- 의사결정나무
- Oracle ASSM
- Spark Data Read
- 리눅스 환경변수
- Linux
- git init
- 앙상블
- Spark 튜닝
- 랜덤포레스트
- 오라클 데이터 처리방식
- Today
- Total
[Alex] 데이터 장인의 블로그
데이터 분석을 위한 통계(PCA - 주성분분석) feat.python 본문
쉽게쉽게 떠올리자.
'주성분 분석'
주성분분석하면 생각해야할 용어들. 공분산 행렬, 벡터 등 여러가지들이 있습니다. 하지만 이것들은 주성분분석을 이해하고 떠올리는데 아무런 도움을 주지 않으므로 나름대로 쉽게 정리해보려고 합니다. (정말 제 나름대로..)
주성분이란 전체 데이터(columns: 변수들)의 분산을 가장 잘 설명하는 '성분'이라고 할 수 있습니다. 주성분 분석이란 말 그대로 여러개의 변수들의 분산을 활용하여 대표적인 변수들을 추출해내는 과정이라고 할 수 있습니다.
차원의 저주
차원의 저주란, columns 수가 늘어날수록 표현해야하는 데이터 범위가 점점 커지게 되어 발생하는 문제입니다. 예를들어, 충분하지 않은 데이터 수로 모델을 구성하게 되었을 때는 모델의 '과적합(overfitting)' 문제가 나타날 수 있습니다. 차원이 높아질수록 데이터의 밀도가 기하급수적으로 줄어들기 때문입니다.
차원의 저주가 나타낼 때, 두가지 방법으로 문제를 해결할 수 있습니다.
1. Feature Selection (변수 선택)
직역한 그대로 몇몇의 변수들만 정하고 나머지 변수들은 버리는 방법입니다. 이때는 중첩되는 변수가 있는지 확인해보고 상관계수나 VIF(다중공선성)가 높은 변수들 중 하나를 삭제합니다. 모델에 많은 영향을 주는 변수들을 우선적으로 찾아내는 방법으로도 해결이 가능하다고 합니다.(Variable Importance 기준)
2. Feature Extraction (변수 추출)
변수 추출 방법은 다른 변수들을 삭제하기보다는 '조합' 하여 새로운 변수로 만들어내는 작업을 뜻합니다. 대표적으로 오늘 우리가 공부하는 PCA(주성분분석) 방법이 있습니다.
차원의 축소, 데이터의 압축
주성분 분석의 대표적인 의미는 '데이터 압축' 입니다. '내가 보고있는 데이터의 변수가 너무 많은데, 이것을 종합적으로 나타내고 분석에 사용할 수 없을까?'라는 생각이 든다면, 주성분 분석을 수행하는 경우가 많습니다.
또한 '시각화'를 위해서 차원을 줄이는 경우도 많습니다. 내가 가지고 있는 변수의 수가 3개 이상이라면, 3차원으로 설명하지 못한다면 PCA를 통해 차원을 줄여준 이후 그래프로 나타내는 경우가 존재합니다.
여러 변수의 정보를 '압축'하여 적은 수의 변수로 나타낸다. |
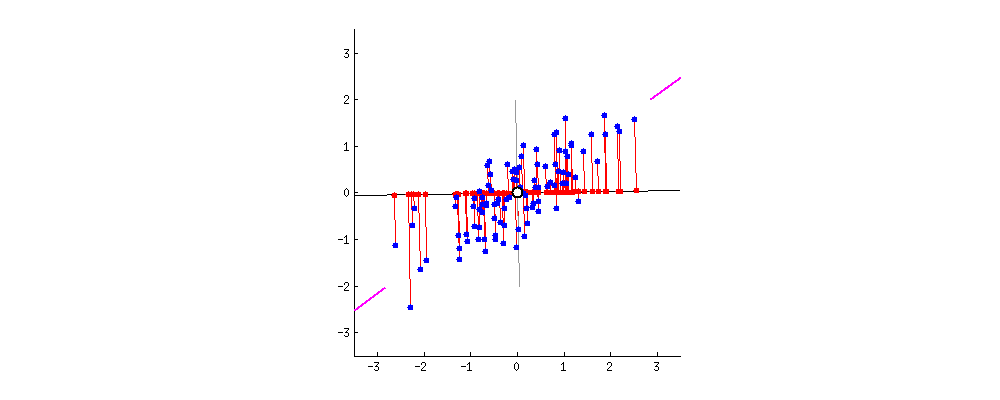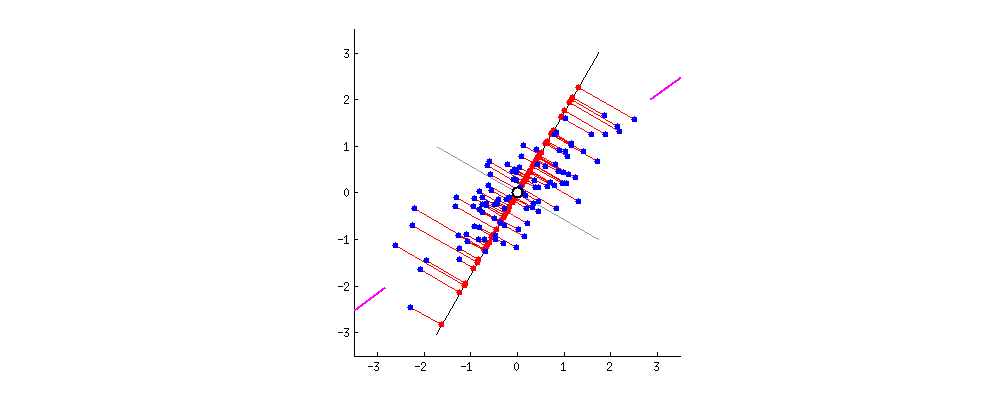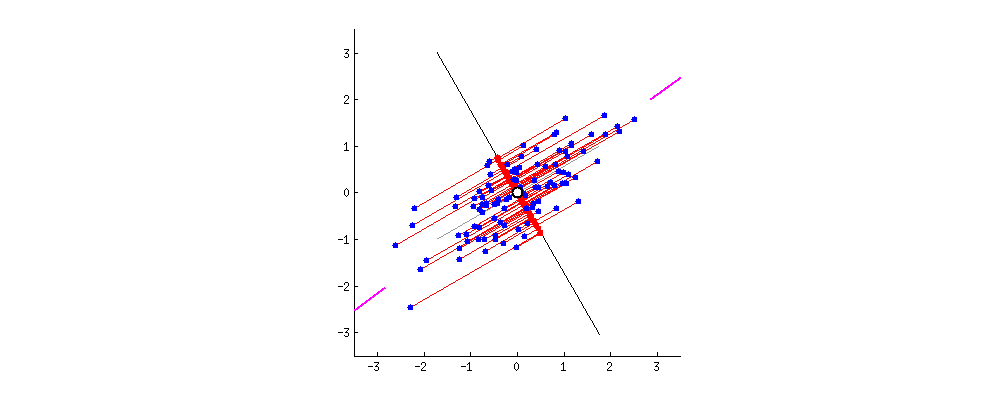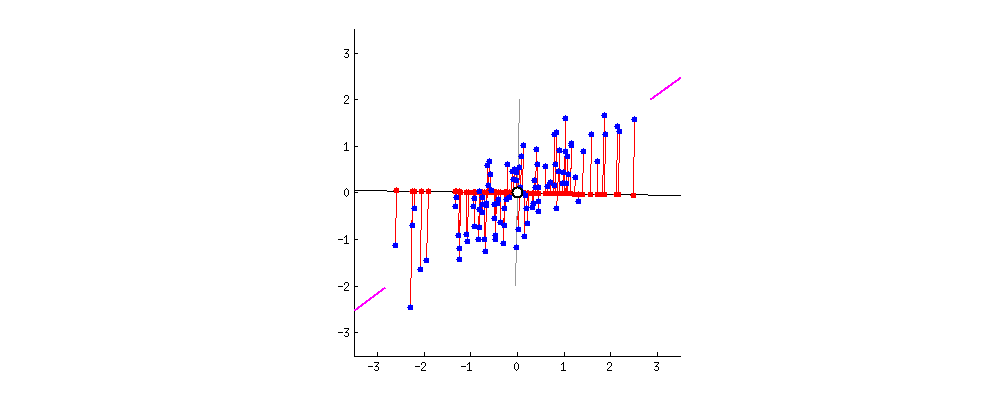
만약 내가 데이터를 압축하는데 하나하나 데이터가 어느정도로 모델에 중요한지 모른다면? 되도록 데이터 유실이 적도록 추출하고 싶을 것입니다. 때문에 주성분 분석을 진행할때는 본래의 변수들의 '분산'을 최대한으로 가져올 수 있도록 합니다. 여기서 분산은 곧 정보량이라고 생각하게 됩니다.
분산 = 정보량
Python 스크립트와 함께 주성분 분석을 살펴봅니다.
출처: 공공데이터포털
데이터는 제가 예전에 따릉이 데이터를 가지고 Clustering을 진행해보려고 했을때 만들어뒀던 예시 데이터로 한번 사용해보겠습니다.
+) 각 정류소당 따릉이 자전거 이용관련 데이터를 핸들링한 결과입니다.
1. 필요한 라이브러리를 호출합니다.
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.decomposition import PCA
# 필요한 패키지와 라이브러리를 가져옴
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
%matplotlib inline
2. 그래프 출력에 필요한 설정을 진행합니다.
# minus font
mpl.rcParams['axes.unicode_minus'] = False
# customize matplitlib
plt.rcParams["figure.figsize"] = (20,15)
plt.rcParams['axes.titlesize'] = 20
plt.rcParams['axes.labelsize'] = 15
plt.rcParams['font.size'] = 15
3. 데이터를 불러옵니다.
data = pd.read_csv("dda_bicycle.csv")
data
총 32열을 가지고 있는 데이터입니다. 클러스터링을 하기에도, 그래프에 나타내기도 어려운 데이터네요.

4. 우리가 가지고 있는 데이터의 값의 '단위' 및 '크기'에 따라서 데이터가 분산량이 왜곡될 수 있기 때문에 표준화를 진행합니다.
# 열별로 scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_scale = pd.DataFrame(scaler.fit_transform(data), columns=data.columns, index = data.index)
5. 표준화된 데이터로 주성분분석을 진행합니다. 고유값을 기준으로 설명할 수 있는 분산량을 나타내봅니다.
# PCA 주성분분석
pca = PCA(random_state=1107)
X_p = pca.fit_transform(data_scale)
pd.Series(np.cumsum(pca.explained_variance_ratio_))
6. 고유값이 설명가능한 분산량이 95%에 해당하는 지점이 3번째 주성분 값이라는 것을 알 수 있습니다.
percent_variance = np.round(pca.explained_variance_ratio_* 100, decimals =2)
columns = []
for i in range(len(percent_variance)):
columns.append(f'PC{i+1}')
ax = plt.bar(x = range(len(percent_variance)), height=percent_variance, tick_label=columns)
plt.ylabel('Percentate of Variance Explained')
plt.xlabel('Principal Component')
plt.title('PCA Scree Plot')
plt.show()
7. 3개의 주성분으로 각각의 정류소가 어떻게 표현되는지 그래프로 나타냅니다.
X_pp = pd.DataFrame(X_p[:,:3], columns = ['PC1','PC2','PC3'], index = data.index)
X_pp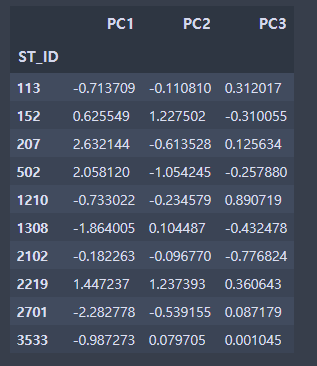
fig = plt.figure()
ax = fig.gca(projection = '3d')
ax.scatter(X_p[0],X_p[1],X_p[2], s=100, c = data.index)
plt.show()
이외에도 서포트 벡터 머신을 활용한 PCA , 데이터 수가 많을 때 사용하는 Incremental PCA 등 다양한 방법들이 있습니다. 해당 방법들은 학습을 더 진행한 이후 포스팅하도록 하겠습니다. 감사합니다.
+ ) 주성분 분석을 이해하기 위한 첨언은 댓글을 남겨주시면 감사하겠습니다!
'Statistic' 카테고리의 다른 글
| 데이터 분석을 위한 통계(카이스퀘어 검정) feat. python (2) | 2020.05.26 |
|---|---|
| 데이터 분석을 위한 통계(ANOVA) feat. python (0) | 2020.05.10 |
| 데이터 분석을 위한 통계(t-test) feat. python (2) | 2020.05.10 |


