
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- BFS
- Oracle 논리적 저장 구조
- Python
- 통계분석
- 데이터 분석
- Spark Data Read
- Decision Tree
- enq: FB - contention
- 추천시스템
- CF
- 리눅스 환경변수
- git 기본명령어
- 네트워크
- git stash
- 오라클 데이터 처리방식
- Collaborative filtering
- Spark 튜닝
- 의사결정나무
- 데이터분석
- eda
- 알고리즘
- airflow 정리
- Linux
- git init
- Oracle ASSM
- 앙상블
- Spark jdbc parallel read
- 랜덤포레스트
- SQL
- 배깅
- Today
- Total
[Alex] 데이터 장인의 블로그
[Data driven Marketing] 코호트 분석 (cohort analysis) feat. python 본문
[Data driven Marketing] 코호트 분석 (cohort analysis) feat. python
Alex, Yoon 2020. 6. 28. 15:49코호트 분석
코호트 분석을 검색하면 나오는 대표적인 이미지는 다음과 거의 대부분 비슷합니다.

하지만 회사에서는 코호트 분석을 지칭해서 이렇게 이야기하지 않습니다. (적어도 제가 다녔던 회사에서는)
"OO님~ 내일까지 고객 데이터 코호트 분석해서 전달 주세요!" /
"코호트 분석을 진행해보니 고객 성향이 어쩌고 저쩌고 ~"
저는 주로 아래의 형태의 방법으로 코호트 분석을 진행했던 것 같습니다.

코호트 = 동질집단
사전적 의미로 코호트는 '동질집단'을 뜻합니다. 예를들어 위에서처럼 '4월에 구매했던 회원'이 '코호트 집단'이 되는 것이고 해당 코호트 집단의 변화(주로 Retention)를 분석하는 것이 바로 코호트 분석입니다.
코호트 분석의 정의
코호트 분석은 기간/ 속성(회원, 상품) / 고객 관심사 등 여러 가지 카테고리에서 공통의 특성을 갖는 유저를 찾는 분석 방법입니다. 말만 거창하고 접근하기 어려운 것 같지만 단순히 이야기해서 데이터를 압축하고 한눈에 확인하기 위해 만드는 피벗과 비슷한 방법론이라고 생각하면 됩니다.
ex)
1월, 2월, 3월 .... 12월에 가입한 회원들의 집합 -> 가입 Month 를 기준으로 한 코호트 집단
가입일을 기준으로 한 집단들의 Retention(재구매 or 재방문) 분석 -> 코호트 분석
최근들어서는 유저 행동을 분석할 수 있는 모바일 앱 환경, 웹 환경들이 많이 발전되었기 때문에
코호트 분석 = 유저 행동 데이터 분석
이라고 생각하는 사람들도 많아진 듯합니다. 필자인 저는 웹 접근, 로그인, 클릭, 구매 전환 등 이러한 패턴을 살펴본 적이 없었기 때문에 웹, 앱 상에서의 유저 행동이 아닌 저의 경험을 빗대어서 설명하고자 합니다.
CRM (데이터 마케팅)에서의 코호트 분석
주제 ex. 20대 여성, 운동복을 좋아하는 그룹, 구매 빈도 2회 이상, 최근 구매하고 난 이후의 기간 1개월 미만 등, 사용자 이탈 현황, 예측
코호트 분석의 가장 주요한 목적은 비즈니스 인사이트를 얻는 것입니다. 마케팅에 필요한 고객 특성을 파악하고 ACTION을 실행하거나 ACTION을 실행한 이후 고객의 행동 패턴을 분석하기 위함입니다. (마케팅 효과 분석의 측면)
또한 세부적인 분석을 실행하기 전, 인사이트를 빠르게 얻고자 할 때 사용하는 단순한 방법이기도 합니다. 오늘은 파이썬 스크립트와 함께 코호트 분석을 구현해봅니다.
1. 라이브러리를 호출합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
pd.set_option('max_columns', 50)
mpl.rcParams['lines.linewidth'] = 2
%matplotlib inline
2. 분석 대상이 될 데이터를 불러오고, 구조와 컬럼 속성 등을 확인합니다.
df = pd.read_excel("relay-foods.xlsx", sheet_name = 'Purchase') # Purchase
df.head()
데이터는 일반적인 고객 주문데이터 (Sales 데이터)입니다. 구매 내역에 따라서
구매번호 : Order Id
구매시간 : OrderDate
사용자번호 : UserId
구매금액 : Total Charges의 변수들을 나타냅니다.
이외 나머지 변수들은 사용하지 않으므로 생각하지 않기로 합니다.
Commonid
Pubid
Pickupdate
분석 주제 or 기준 변수
분석의 목표는 다음과 같다고 설정합니다.
첫 번째 구매행동 이후 몇 개월까지 구매행위가 지속되는가?, 구매주기를 대략적으로 얼마큼 되는가?,
첫 구매 날짜(브랜드 인입 시기)에 따른 최근 구매 패턴(구매, 비구매) 비교 등
상기 분석 목표에 따라서 변수를 설정하여야 하는데, 여기에서는 '첫구매'일로 설정하겠습니다.
(가입일이 있다면 보통 가입일에 따라서 설정하기도 합니다.) ex. 가입일 후 첫 구매, 재구매, N번째 구매일
3. 기준이 되는 변수(Order date)를 YYYY-MM 형태로 만들어줍니다. (년월 형식)
df['OrderPeriod'] = df.OrderDate.apply(lambda x: x.strftime('%Y-%m'))
df.head()
4. 각각 사용자의 첫 구매월을 추출하기위해 UserId를 index로 설정한 이후 groupby 함수를 사용하여 (기준 index level = 0) 'CohortGroup' 변수를 추가합니다.
df.set_index('UserId', inplace=True)
# 고객 각각의 첫 구매기간 추출
df['CohortGroup'] = df.groupby(level=0)['OrderDate'].min().apply(lambda x: x.strftime('%Y-%m'))
df.reset_index(inplace=True)
df.head()

데이터 오류가 없는지 검증도 실시합니다. (항상 데이터를 확인해보는 습관을 갖는 것이 좋습니다.)
df.query("OrderPeriod != CohortGroup")
df.query("UserId == 47")
5. 첫구매일(년월)와 구매 날짜(년월)를 기준으로 하여 고객 수, 주문 수, 총매출 합계를 계산합니다.
# CohortGroup & OrderPeriod
grouped = df.groupby(['CohortGroup', 'OrderPeriod'])
cohorts = grouped.agg({'UserId': pd.Series.nunique, # DISTINCT COUNT
'OrderId': pd.Series.nunique,
'TotalCharges': np.sum}) # SUM
cohorts.rename(columns={'UserId': 'TotalUsers',
'OrderId': 'TotalOrders'}, inplace=True)
cohorts.head()
위의 결과를 해석해보자면 2009년 1월에 첫구매한 고객 수가 22명, 주문 횟수가 30번, 총매출 합계가 1850원입니다.
이후 2월에는 22명 중 8명만이 구매행동을 보였으며, 3월에는 10명, 4월에는 9명만이 구매행동을 보였습니다. 이는 첫 번째 1월에 구매행동을 보인 22명에 대한 구매 유무만을 측정하여 표로 나타낸 것으로 22명의 회원이 매달 연속적인 구매를 했다고 볼 수는 없습니다.
6. <년월 - 년월>의 패턴을 <년월 - 소요기간(월)>로 변환하여 보기위해 다음과 같은 함수를 만들어줍니다.
# Label the CohortPeriod for each CohortGroup
def cohort_period(df):
"""
Creates a `CohortPeriod` column, which is the Nth period based on the user's first purchase.
Example
-------
Say you want to get the 3rd month for every user:
df.sort(['UserId', 'OrderTime', inplace=True)
df = df.groupby('UserId').apply(cohort_period)
df[df.CohortPeriod == 3]
"""
df['CohortPeriod'] = np.arange(len(df)) + 1
return dfcohorts = cohorts.groupby(level=0).apply(cohort_period)
cohorts.head()
7. 데이터가 맞게 정리가 되었는지 확인합니다.
* assert 함수: 괄호 안에 결과가 False라면 예외(exception)가 발생합니다.
x = df[(df.CohortGroup == '2009-01') & (df.OrderPeriod == '2009-01')]
y = cohorts.ix[('2009-01', '2009-01')]
# 가정 설정문 / 이는 단순히 에러를 찾는것이 아니라 값을 보증하기 위해 사용된다.
assert(x['UserId'].nunique() == y['TotalUsers'])
assert(x['TotalCharges'].sum().round(2) == y['TotalCharges'].round(2))
assert(x['OrderId'].nunique() == y['TotalOrders'])x = df[(df.CohortGroup == '2009-05') & (df.OrderPeriod == '2009-09')]
y = cohorts.ix[('2009-05', '2009-09')]
assert(x['UserId'].nunique() == y['TotalUsers'])
assert(x['TotalCharges'].sum().round(2) == y['TotalCharges'].round(2))
assert(x['OrderId'].nunique() == y['TotalOrders'])
8. Retention 결과를 (%) 비율로 나타내기 위해 각각 첫 구매일(년월)에 따른 회원수를 구합니다.
cohorts.reset_index(inplace=True)
cohorts.set_index(['CohortGroup', 'CohortPeriod'], inplace=True)
cohort_group_size = cohorts['TotalUsers'].groupby(level=0).first()
cohort_group_size.head()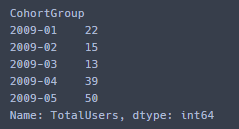
- 2009-01 에 첫 구매한 회원수 22명 , 2월에 첫 구매한 회원수 15명
9. '8.'에서 생성한 결과를 divide 함수를 활용해서 각 변수를 나누어줍니다.
user_retention = cohorts['TotalUsers'].unstack(0).divide(cohort_group_size, axis=1)
user_retention.head(10)
10. 결과를 그래프로도 나타내 봅니다.
user_retention[['2009-06', '2009-07', '2009-08']].plot(figsize=(10,5))
plt.title('Cohorts: User Retention')
plt.xticks(np.arange(1, 12.1, 1))
plt.xlim(1, 12)
plt.ylabel('% of Cohort Purchasing');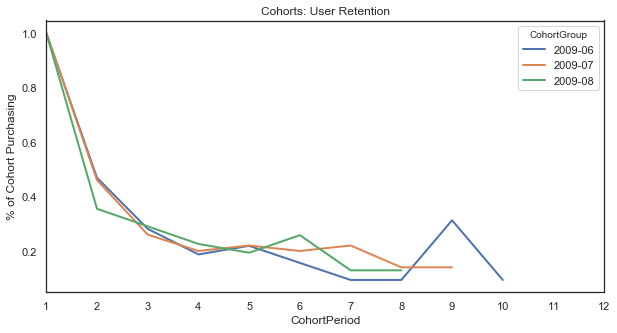
11. 이제 가장 일반적인 Cohort 분석의 그래프 형태로 나타내 봅니다.
# Creating heatmaps in matplotlib is more difficult than it should be.
# Thankfully, Seaborn makes them easy for us.
# http://stanford.edu/~mwaskom/software/seaborn/
import seaborn as sns
sns.set(style='white')
plt.figure(figsize=(12, 8))
plt.title('Cohorts: User Retention')
sns.heatmap(user_retention.T, mask=user_retention.T.isnull(), annot=True, fmt='.0%');

그래프는 각각 브랜드에 유입된 시기를 비교하여 첫구매 이후 고객들의 구매패턴을 나타낸 것입니다.
2009년 07월에 유입된 고객들의 패턴을 기준으로 살펴보면 첫 구매 이후 한 달 뒤 46%가 구매행동을 보였고 8개월이 지난 후에는 14%만이 구매행동을 보였습니다. 여기서 자세히 살펴보면 최근 기준으로 구매행동을 보인 고객들의 유입 날짜(년월)를 확인할 수 있습니다.
12. 다음과 같이 최근 발생한 매출의 회원들의 첫 구매일 분포도 확인할 수 있습니다.
import seaborn as sns
sns.set(style='white')
plt.figure(figsize=(24, 8))
plt.title('Cohorts: User Retention & Amount of this month')
sns.heatmap(cohorts['TotalCharges'].unstack(0).T.fillna(0).astype('int'), mask=user_retention.T.isnull(), annot=True, fmt= '0');
ref.
http://www.gregreda.com/2015/08/23/cohort-analysis-with-python/
'Data driven marketing' 카테고리의 다른 글
| [Data driven Marketing] AARRR 분석, Funnel 분석 , 그로스 해킹, CAC (0) | 2020.06.08 |
|---|
