
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- git stash
- 데이터 분석
- Decision Tree
- 앙상블
- git init
- 알고리즘
- 통계분석
- CF
- Oracle 논리적 저장 구조
- enq: FB - contention
- 리눅스 환경변수
- 오라클 데이터 처리방식
- Spark jdbc parallel read
- 네트워크
- 의사결정나무
- Oracle ASSM
- Linux
- 데이터분석
- eda
- Spark Data Read
- Collaborative filtering
- git 기본명령어
- SQL
- Spark 튜닝
- 랜덤포레스트
- 배깅
- BFS
- 추천시스템
- Python
- airflow 정리
- Today
- Total
[Alex] 데이터 장인의 블로그
데이터 분석을 위한 SQL 쿼리 - 2. EDA를 정복해보자 본문
SQL을 활용한 EDA
오늘은 데이터 분석의 꽃, EDA과정을 SQL로 수행해보는 시간을 가져보도록 하겠습니다.
굳이 Python이나 R로 작업을 하지 않고 SQL로 하는 이유가 있느냐.. 라는 질문을 받은적도 있습니다. 저는 Python, R로 작업을 진행하는 것보다 SQL이 더 '편하고 빠르다'라고 생각하기 때문입니다. 각자 자신이 편한 tool을 사용하여 EDA를 실시하는 것이 가장 바람직하다고 생각합니다. (저는 가끔 귀차니즘이 발생할 때 Tableau로 작업하기도 합니다.... 굳이 비싼 프로그램을 EDA로...ㅎ )
거의 Data 자체가 데이터베이스(DB서버)에 저장되어있는 경우가 보통이며 굳이 이를 Python으로 호출해서 보지 않아도 속도 측면, 효율성 측면에서 SQL 자체가 훨씬 좋다고 생각합니다.(어디까지나 저의 생각입니다!) +) SQL은 나중에 분석 MART를 구성하거나 시각화를 위한 MART 생성에서도 쓰일 것이기 때문에 배워두는 것도 중요하다고 생각합니다. 전처리해서 Python 분석 작업의 데이터로 가져가는 것이 더욱 효율적일 것 같습니다.
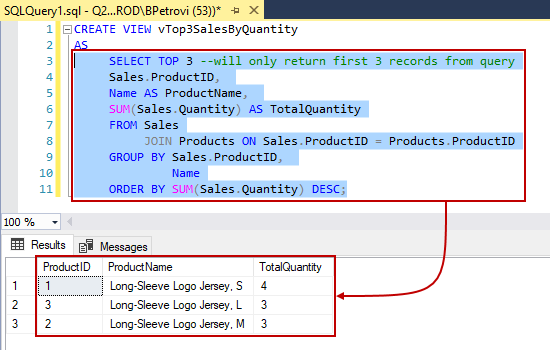
데이터 설명
기업의 매출데이터나 대량의 데이터를 가지고 EDA를 진행해보면 좋겠다고 생각이 들었지만 개인정보 보호 문제 등 여러 민감한 문제들이 존재하기 때문에 공공데이터 포털에서의 서울시 공유자전거 '따릉이' 이용내역 데이터를 가지고 EDA를 수행해보겠습니다.
데이터는 공공데이터 포털 등에서 쉽게 구할 수 있습니다. 데이터는 MSSQL에 입력해서 진행해보도록 하겠습니다. 자세한 사항은 이전 포스팅에 담겨져 있습니다. 아래 글을 참고하시면 됩니다.
2020/06/10 - [SQL] - 데이터 분석을 위한 SQL 쿼리 - SQL 무료버전 설치하기 (MSSQL EXPRESS, SSMS 설치)
데이터 분석을 위한 SQL 쿼리 - SQL 무료버전 설치하기 (MSSQL EXPRESS, SSMS 설치)
Microsoft SQL Server 무료버전 설치하기 오늘은 혼자서 SQL를 공부해야 하는데.. SQL Server를 가지고 있는 학생이나 일반인 분들을 위해 MSSQL 무료버전을 설치하고 데이터 셋을 입력하는 방법을 공부해��
alex-blog.tistory.com
EDA를 수행해 볼 데이터는 이전에 입력하였던 위의 글에서 입력했던 '서울시 공유자전거 따릉이 데이터' 입니다.

데이터는 2019년도 11월 데이터를 모두 가져와서 EDA를 진행해보겠습니다. 데이터를 SQL에 입력하는 방법은 위 포스팅을 참고해주시면 됩니다.
차례차례 쿼리를 작성해보며 분석을 시작해보겠습니다.
1. 가장 먼저 데이터를 UNION 해주겠습니다! 저는 UNION ALL을 사용했습니다.
* 같은 목적으로 사용되는 함수이지만 UNION ALL 은 각각 행의 중복 유무를 확인하지 않기 때문에 훨씬 더 빠릅니다. 데이터가 중복되지 않는다는 사실을 인지하고 있다면 UNION ALL을 사용하시는게 더욱 효율적입니다.
* #BASE : 임시테이블입니다. 테이블을 데이터베이스에 새로 저장하는 것이 부담스럽거나, 이 쿼리를 작성할 때만 사용할 테이블이라면 '임시테이블'을 사용하시는 것을 추천드립니다. 임시 테이블은 SQL이 종료되는 즉시 자동으로 사라집니다.
USE DATA
SELECT *
INTO #BASE
FROM (
SELECT *
FROM SAMPLE_DATA
UNION
ALL
SELECT *
FROM SAMPLE_DATA2
) A 
간단하게 데이터를 설명해보자면
BK_ID : 따릉이 자전거 ID
DP_DT : 대여시간
ST_ID : 대여소 ID
AR_DT : 반납시간
AR_ST_ID : 반납 대여소 ID
MT : 사용시간
DISTC : 이동거리
2. 정류소 숫자와 전체 데이터 셋의 크기를 측정합니다.
확인을 하는 이유는 정류소 별로 GROUP BY를 하게 될 때의 대략적인 소요시간과 전체 쿼리 작업시간을 대충 짐작하기 위함입니다. ex) 140만행 정도면 어떻게 쿼리를 짜든 문제가 되진 않겠지?
SELECT COUNT(DISTINCT ST_ID)
FROM #BASE
SELECT COUNT(*)
FROM #BASE
3. 일별 이용량을 살펴봅니다.
COUNT(*) 사용하여 사용횟수를 측정합니다. 보통 USE_ID를 사용하거나 고유 ID를 세어주는 방식을 행하는데 데이터 구조가 이렇다보니 행을 세어주는 작업을 진행하겠습니다. 사용시간과 거리를 AVG() 함수를 사용하여 평균값을 구해줍니다.
-- 1. 일별 이용량 비교
SELECT CONVERT(VARCHAR, DP_DT, 112) DT
, COUNT(*) CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
GROUP
BY CONVERT(VARCHAR, DP_DT, 112)
ORDER
BY 1 ASC 
이렇게 TABLE 형태로 살펴보니 비교를 할 수 없습니다. 엑셀로 가져가 간단히 그래프로 살펴보겠습니다.
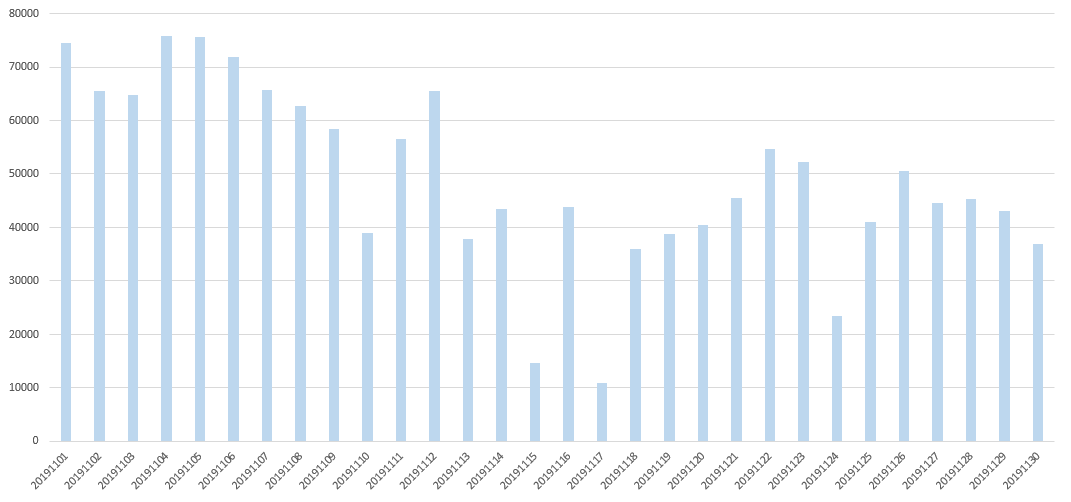
생각보다 주말 이용량과 주중 이용량이 확실히 구분지어지지 않습니다. 사용량이 급격히 떨어지는 날은 비가 왔을 가능성이 클 것 같습니다.
4. 주말과 주중 이용량을 비교해보겠습니다. DATEPART 함수로 날짜 데이터를 '요일'로 바꿔준 뒤에 수치를 비교합니다. 여기서 생각해봐야할 문제가 있습니다.
현재 데이터는 한 줄(ROW)당 하나의 이용내역이라고 생각할 수 있습니다. 주말의 '하루'당 평균 이용량을 비교하려면 우선 1) 일별 이용량(절대치)이 계산되어야 합니다. 2) 그 이후 1)의 결과를 바탕으로 평균을 구해야합니다.
항상 어떤 '기준'으로 평균값을 산출해낼지를 생각해서 하위쿼리를 사용해야 합니다.
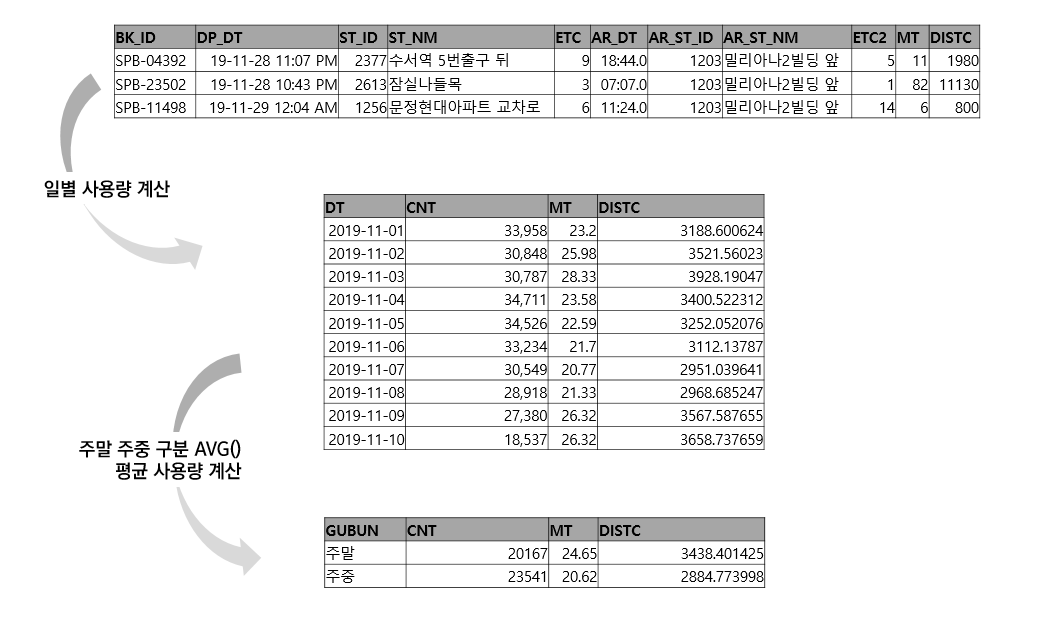
-- 2. 주말, 주중 이용량 비교(절대치)
SELECT DATEPART(WEEKDAY, DT)
, AVG(CNT)
, AVG(MT)
, AVG(DISTC)
FROM (
SELECT CONVERT(DATE, DP_DT) DT
, COUNT(*) CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
GROUP
BY CONVERT(DATE, DP_DT)
) A
GROUP
BY DATEPART(WEEKDAY, DT)
ORDER
BY 1 
만약 따릉이 전체 이용량이 아닌 정류소 하나 당 이용량을 비교하고 싶다면 아래와 같이 쿼리를 작성하면 됩니다.
-- 2-1. 주말 주중 구분 정류소 당 이용량 비교
SELECT DATEPART(WEEKDAY, DT)
, AVG(CNT)
, AVG(MT)
, AVG(DISTC)
FROM (
SELECT CONVERT(DATE, DP_DT) DT
, ST_ID
, COUNT(*) * 1.0 CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
GROUP
BY CONVERT(DATE, DP_DT)
, ST_ID
) A
GROUP
BY DATEPART(WEEKDAY, DT)
ORDER
BY 1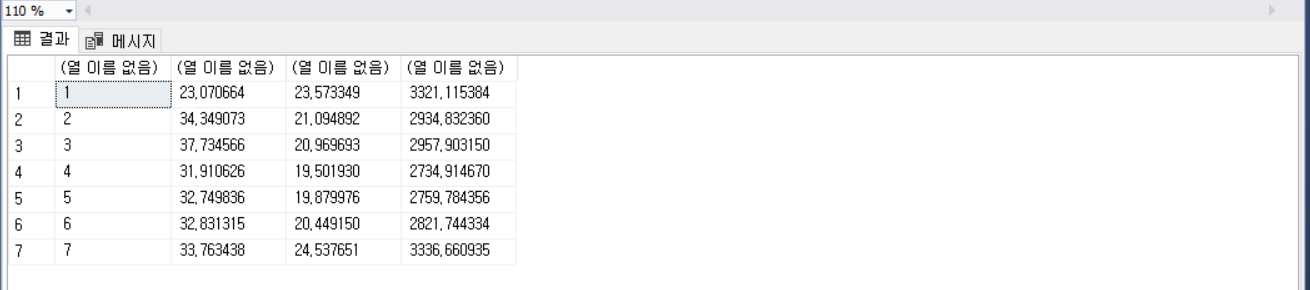
5. 정류소 기준으로 가장 이용량이 많은 곳을 살펴보겠습니다.
-- 3. 순위권 정류장 구하기
SELECT ST_ID
, ST_NM
, COUNT(*)
FROM #BASE
GROUP
BY ST_ID
, ST_NM
ORDER
BY 3 DESC 
TOP 10의 정류소는 어떤 시간에 이용량이 많을까 궁금해졌습니다.
우선은 하위쿼리에서는 ORDER BY 를 사용할 수 없기 때문에 ROW_NUMBER 함수로 순위를 계산해줍니다 .
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
그리고 해당하는 TOP 10 개의 정류소의 데이터만 가져오기 위해 IN 문 혹은 JOIN 문을 활용합니다. 직관적으로 이해하기 쉬운 IN문을 사용해보겠습니다.
SELECT *
FROM #BASE
WHERE ST_ID IN (
SELECT DISTINCT ST_ID
FROM (
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
) A
WHERE RNK <= 10 )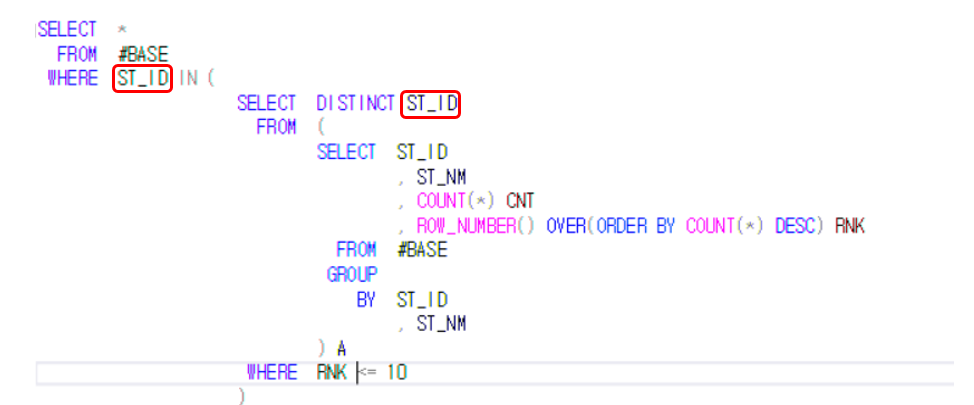
이렇게 쿼리를 짜면 #BASE 테이블에서 ST_ID가 IN 함수 안에 들어가있는 값을 확인하기 때문에 원하는 데이터를 가져올 수 있습니다. 쿼리의 성능을 생각한다면 JOIN 절을 활용해서 같은 데이터를 가져올 수 있습니다. (여기서 주의할 점은 JOIN하는 하위쿼리의 값이 항상 DISTINCT 한 값이어야 합니다. ) 중복 JOIN이 발생하지 않게 이 점은 항상 유의해야합니다.
SELECT A.*
FROM #BASE A
JOIN (
SELECT DISTINCT ST_ID
FROM (
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
) A
WHERE RNK <= 10
) B
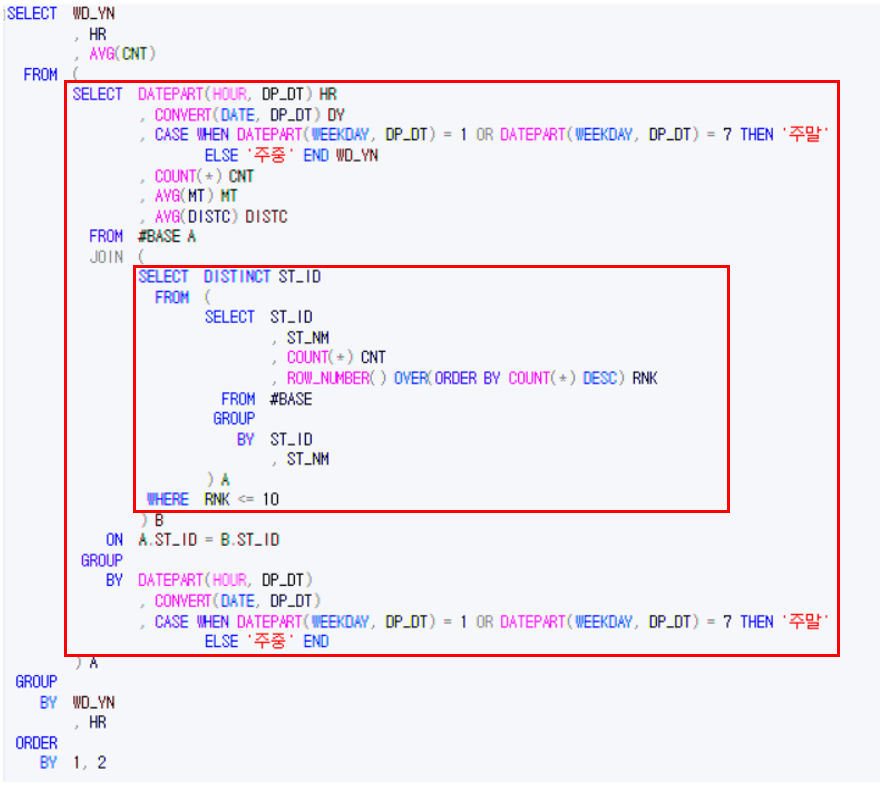
ON A.ST_ID = B.ST_ID 해당 데이터를 활용해서 상위 10개의 정류소의 시간별 평균 이용량을 구해보겠습니다.
하위쿼리를 여러개 사용합니다.
SELECT WD_YN
, HR
, AVG(CNT)
FROM (
SELECT DATEPART(HOUR, DP_DT) HR
, CONVERT(DATE, DP_DT) DY
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END WD_YN
, COUNT(*) CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE A
JOIN (
SELECT DISTINCT ST_ID
FROM (
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
) A
WHERE RNK <= 10
) B
ON A.ST_ID = B.ST_ID
GROUP
BY DATEPART(HOUR, DP_DT)
, CONVERT(DATE, DP_DT)
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END
) A
GROUP
BY WD_YN
, HR
ORDER
BY 1, 2 결과를 엑셀로 가져가서 그래프로 표현해보겠습니다.

확실히 주중에는 출퇴근 시간에 이용량이 많고 주말은 오후에 점점 사용량이 많아지는 패턴을 보입니다.
이처럼 SQL로 분석 or 간단한 EDA를 실시할 때에는 GROUP BY, 하위쿼리를 자주 사용합니다. 때문에 테이블 구분을 지어줄 수 있도록 쿼리를 작성하는 것이 중요합니다.
오늘은 여기까지 EDA를 수행해보겠습니다. 다음에는 이어서 분석을 진행하되 다양한 기준으로 데이터를 살펴보겠습니다.
'SQL' 카테고리의 다른 글
| [MySQL] Linux 환경 세팅 (0) | 2021.10.12 |
|---|---|
| 데이터 분석을 위한 SQL 쿼리 - 3. EDA를 정복해보자 (0) | 2020.06.28 |
| 데이터 분석을 위한 SQL 쿼리 - SQL 무료버전 설치하기 (MSSQL EXPRESS, SSMS 설치) (1) | 2020.06.10 |
| 데이터 분석을 위한 SQL 쿼리 - 1. 데이터 정합성 검사 (0) | 2020.04.20 |
| 데이터 분석, SQL 관련 서적 추천 (0) | 2020.03.08 |



