
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- eda
- enq: FB - contention
- 데이터분석
- 의사결정나무
- 추천시스템
- BFS
- Oracle ASSM
- 통계분석
- Collaborative filtering
- Spark 튜닝
- Oracle 논리적 저장 구조
- 배깅
- 네트워크
- Spark jdbc parallel read
- SQL
- Linux
- git stash
- 데이터 분석
- Decision Tree
- 리눅스 환경변수
- Python
- 앙상블
- airflow 정리
- git init
- git 기본명령어
- 랜덤포레스트
- CF
- 오라클 데이터 처리방식
- Spark Data Read
- 알고리즘
- Today
- Total
[Alex] 데이터 장인의 블로그
데이터 분석을 위한 SQL 쿼리 - 3. EDA를 정복해보자 본문
저번 학습에 이어서 SQL을 활용한 EDA를 학습하겠습니다.
이전글:
2020/06/21 - [SQL] - 데이터 분석을 위한 SQL 쿼리 - 2. EDA를 정복해보자
저번 EDA 분석에서는 다음과 같은 결론까지 지어낼 수 있었습니다.
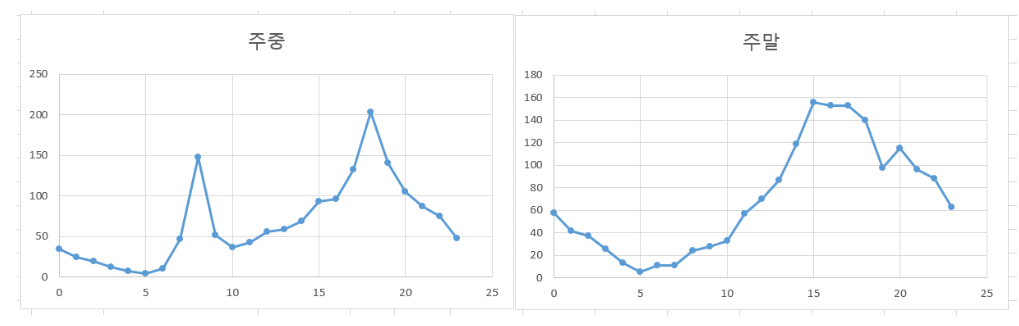
이번 분석에서는 전체 정류소를 대상을 대상으로 특성을 파악하는 것이 아닌, 각각의 정류소의 특성을 파악해보는 방법으로 분석을 진행하도록 하겠습니다.
1. 저녁, 출근, 심야 시간대의 각각 정류소의 이용건수를 비교해보겠습니다.
-- 1. 저녁, 출근, 심야만 가져와서 각 정류소 특성 파악하기
SELECT ST_ID
, WD_YN
, CASE WHEN HR >= 7 AND HR <= 9 THEN '출근'
WHEN HR >= 17 AND HR <= 19 THEN '퇴근'
WHEN HR >= 23 OR HR <= 1 THEN '심야' END HR_GUBUN
, AVG(CNT) CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM (
SELECT ST_ID
, DATEPART(HOUR, DP_DT) HR
, CONVERT(DATE, DP_DT) DY
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END WD_YN
, COUNT(*) * 1.0 CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
GROUP
BY ST_ID
, DATEPART(HOUR, DP_DT)
, CONVERT(DATE, DP_DT)
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END
) A
GROUP
BY ST_ID
, WD_YN
, CASE WHEN HR >= 7 AND HR <= 9 THEN '출근'
WHEN HR >= 17 AND HR <= 19 THEN '퇴근'
WHEN HR >= 23 OR HR <= 1 THEN '심야' END

2. HR_GUBUN 이 NULL 나오는 현상을 없애주고 전에 비교해보았던 이용량 TOP 10의 정류소만을 비교하기 위해 IN 함수를 사용하겠습니다.
-- 1. 저녁, 출근, 심야만 가져와서 각 정류소 특성 파악하기
SELECT ST_ID
, WD_YN
, CASE WHEN HR >= 7 AND HR <= 9 THEN '출근'
WHEN HR >= 17 AND HR <= 19 THEN '퇴근'
WHEN HR >= 23 OR HR <= 1 THEN '심야' END HR_GUBUN
, AVG(CNT) CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM (
SELECT ST_ID
, DATEPART(HOUR, DP_DT) HR
, CONVERT(DATE, DP_DT) DY
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END WD_YN
, COUNT(*) * 1.0 CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
GROUP
BY ST_ID
, DATEPART(HOUR, DP_DT)
, CONVERT(DATE, DP_DT)
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END
) A
WHERE CASE WHEN HR >= 7 AND HR <= 9 THEN '출근'
WHEN HR >= 17 AND HR <= 19 THEN '퇴근'
WHEN HR >= 23 OR HR <= 1 THEN '심야' END IS NOT NULL
AND ST_ID IN (
SELECT DISTINCT ST_ID
FROM (
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
) A
WHERE RNK <= 10
)
GROUP
BY ST_ID
, WD_YN
, CASE WHEN HR >= 7 AND HR <= 9 THEN '출근'
WHEN HR >= 17 AND HR <= 19 THEN '퇴근'
WHEN HR >= 23 OR HR <= 1 THEN '심야' END 추가된 부분입니다.

3. raw 데이터 형태로는 비교하기 힘드니 엑셀로 가져가 정류소별로 비교해보겠습니다. (SQL의 최대의 단점은 PIVOTING 인 것같기도.. )

피봇팅해서 결과를 살펴보니 차이가 확실히 나타나는 것 같습니다. 예시로 출퇴근, 나들이 형으로 특성을 구분짓고 실제로 이용시간 분포가 상기 분석 결과와 같은지 확인해보겠습니다.
+ 간단한 피봇팅이지만 궁금하실 분들이 있을지도 몰라 파일 업로드하였습니다.
4. 이용시간 분포를 나타내보도록 하겠습니다. (시간대별 이용시간 분포 조사)
SELECT ST_ID
, HR
, WD_YN
, AVG(CNT)
, AVG(MT)
FROM (
SELECT ST_ID
, DATEPART(HOUR, DP_DT) HR
, CONVERT(DATE, DP_DT) DY
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END WD_YN
, COUNT(*) * 1.0 CNT
, AVG(MT) MT
, AVG(DISTC) DISTC
FROM #BASE
WHERE ST_ID IN (
SELECT DISTINCT ST_ID
FROM (
SELECT ST_ID
, ST_NM
, COUNT(*) CNT
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM #BASE
GROUP
BY ST_ID
, ST_NM
) A
WHERE RNK <= 10
)
GROUP
BY ST_ID
, DATEPART(HOUR, DP_DT)
, CONVERT(DATE, DP_DT)
, CASE WHEN DATEPART(WEEKDAY, DP_DT) = 1 OR DATEPART(WEEKDAY, DP_DT) = 7 THEN '주말'
ELSE '주중' END
) A
GROUP
BY ST_ID
, HR
, WD_YN

결과가 잘 나왔는지 확인하기 위해 마찬가지로 엑셀로 가져가서 비교해보겠습니다.
대표적으로 출근시간대 이용량이 가장 많았던 2701 정류소와 주중 이용량은 극히적고 주말 사용량이 높았던 502 정류소를 비교해보겠습니다.
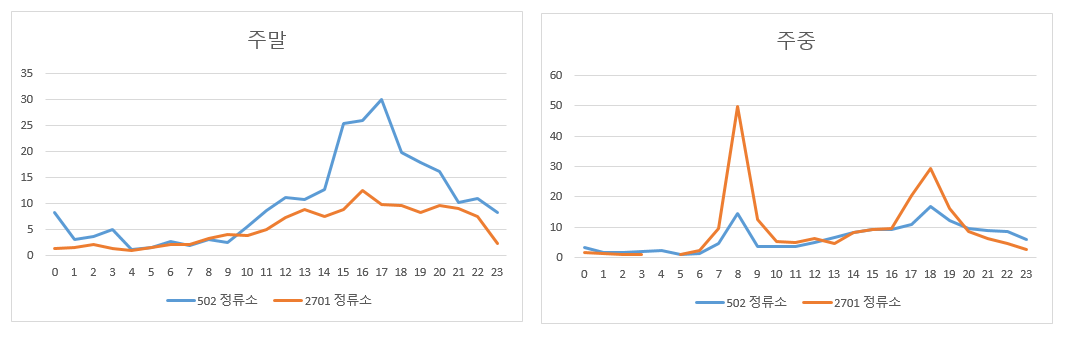
확실히 2701 정류소는 주중 출근, 퇴근시간대에 이용량이 몰려있으며 502 정류소는 주말에 이용량이 많은 것을 확인할 수 있습니다.
두 정류소는 속성이 다르며 고객의 이용패턴 또한 다르다는 것을 확인할 수 있네요.
5. 이전 포스팅에서 날짜별 이용횟수를 비교했을때 급격히 줄어든 날이 있었습니다.
2020/06/21 - [SQL] - 데이터 분석을 위한 SQL 쿼리 - 2. EDA를 정복해보자
데이터 분석을 위한 SQL 쿼리 - 2. EDA를 정복해보자
SQL을 활용한 EDA 오늘은 데이터 분석의 꽃, EDA과정을 SQL로 수행해보는 시간을 가져보도록 하겠습니다. 굳이 Python이나 R로 작업을 하지 않고 SQL로 하는 이유가 있느냐.. 라는 질문을 받은적도 있습
alex-blog.tistory.com

15일: 금요일
17일, 24일: 일요일
입니다.
해당날짜에 비가 왔는지 확인해보겠습니다.

이용량이 급격히 줄어든날엔 강수량이 있는 것으로 나타나는 것을 확인할 수 있습니다. 강수량에 의한 이용량 감소라고 판단할 수 있겠습니다.
강수량 이외에도 시간대별 강수량을 비교해보면 더욱더 자세히 분석이 가능할 것으로 보입니다.
'SQL' 카테고리의 다른 글
| [MySQL] 접속 허용 IP 설정하기 (0) | 2021.10.12 |
|---|---|
| [MySQL] Linux 환경 세팅 (0) | 2021.10.12 |
| 데이터 분석을 위한 SQL 쿼리 - 2. EDA를 정복해보자 (1) | 2020.06.21 |
| 데이터 분석을 위한 SQL 쿼리 - SQL 무료버전 설치하기 (MSSQL EXPRESS, SSMS 설치) (1) | 2020.06.10 |
| 데이터 분석을 위한 SQL 쿼리 - 1. 데이터 정합성 검사 (0) | 2020.04.20 |


