
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 랜덤포레스트
- 통계분석
- 오라클 데이터 처리방식
- airflow 정리
- Spark 튜닝
- Oracle 논리적 저장 구조
- git 기본명령어
- 추천시스템
- 데이터분석
- git stash
- enq: FB - contention
- 네트워크
- 데이터 분석
- Spark jdbc parallel read
- 리눅스 환경변수
- Spark Data Read
- Linux
- 배깅
- 의사결정나무
- BFS
- 알고리즘
- Collaborative filtering
- SQL
- Decision Tree
- Python
- Oracle ASSM
- eda
- CF
- 앙상블
- git init
Archives
- Today
- Total
[Alex] 데이터 장인의 블로그
Spark 프로그래밍 환경 구성 - 1. 로컬모드 설치 본문
환경
OS: Ubuntu 18.04
Python: 3.6.9
사전 설치 필요
Java 설치
Spark JVM 기반인 Scala 로 만들어져 있음.
JAVA 설치가 되어있어야함.
Spark 설치
http://spark.apache.org/downloads
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS. Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spar
spark.apache.org

Ubuntu CLI창에서 wget을 통해 다운로드 받겠습니다.
wget https://mirror.navercorp.com/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
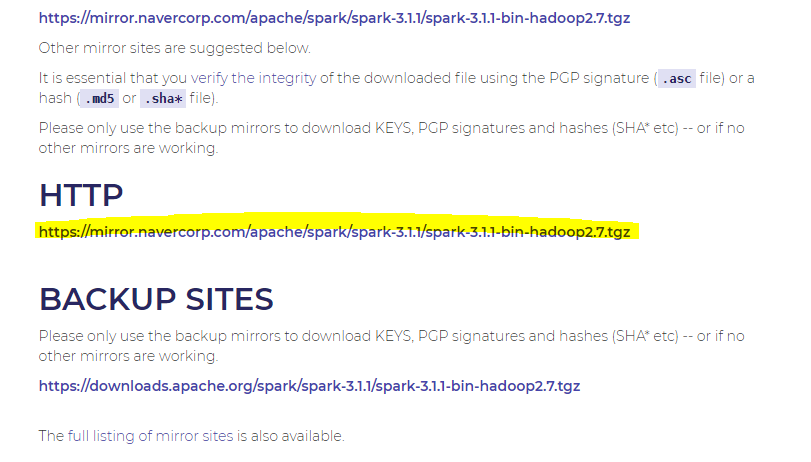
다운로드 후, 원하는 디렉토리에 옮겨서 압축을 풀어줍니다.
압축 풀기
- tar -xf spark-2.3.3-bin-hadoop2.7.tgz
스파크 심볼릭 링크 생성
- ln -s spark-2.3.3-bin-hadoop2.7 spark
PYSPARK SHELL 설정
환경변수 추가 ( .profile 파일 설정 )
- export PYSPARK_PYTHON=python3
python spark 앨리어스 등록 ( .bash_profile 파일 설정 )
- alias pyspark=~/spark/bin/pyspark
자 이제 pyspark 명령어를 활용해서 spark를 실행시켜줄 수 있습니다.
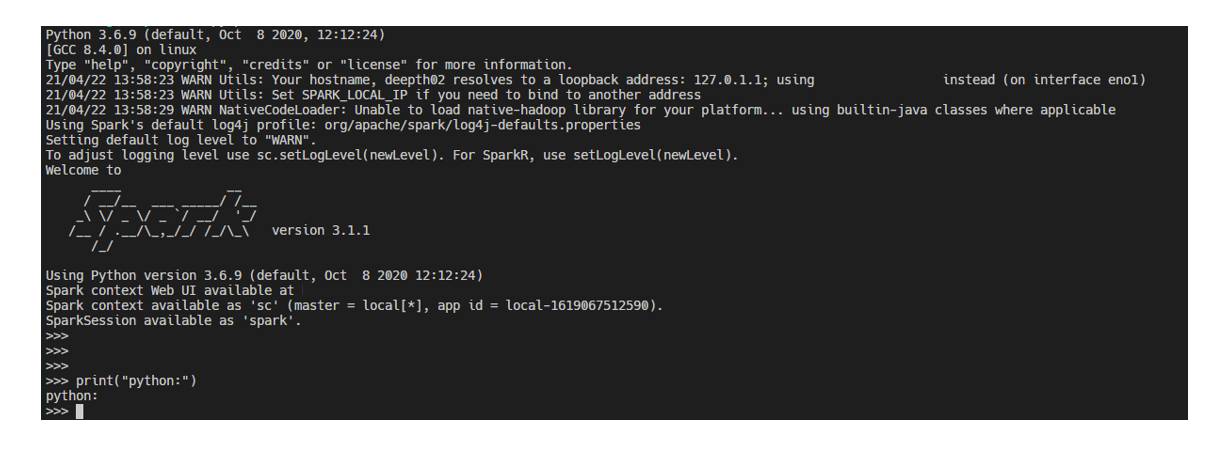
반응형
'Hadoop & Spark' 카테고리의 다른 글
| [JVM] JVM의 Garbage Collector (Feat. 튜닝을 위해서..) (0) | 2023.01.24 |
|---|---|
| [Spark] 성능 튜닝(1) - Data Ingestion (Feat. JDBC Parallel Read) (0) | 2023.01.05 |
| [JVM] 기본 개념 정리 (0) | 2022.12.19 |
| Spark 프로그래밍 - RDD, DataFrame (0) | 2021.05.01 |
| Hadoop 기본 (0) | 2021.02.27 |
'Hadoop & Spark' Related Articles
more



Comments