
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- BFS
- 알고리즘
- git 기본명령어
- enq: FB - contention
- 추천시스템
- 배깅
- 리눅스 환경변수
- Python
- Oracle 논리적 저장 구조
- airflow 정리
- 데이터 분석
- Spark jdbc parallel read
- 오라클 데이터 처리방식
- Collaborative filtering
- Decision Tree
- Oracle ASSM
- SQL
- 앙상블
- CF
- git init
- eda
- 통계분석
- 데이터분석
- 의사결정나무
- git stash
- 랜덤포레스트
- Spark 튜닝
- Linux
- Spark Data Read
- 네트워크
Archives
- Today
- Total
[Alex] 데이터 장인의 블로그
[알고리즘] 4) 퀵 정렬 알고리즘 본문
퀵 정렬은 많은 프로그래밍이 기본으로 채택하는 정렬 알고리즘이다. (프로그래밍 언어 차원에서의 기본적으로 지원되는 정렬함수.)
분할 정복 알고리즘의 하나로, 평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법.
분할 정복(divide and conquer) 방법
- 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하는 전략이다.
분할 정복 방법은 대개 순환 호출을 이용하여 구현한다.

과정 설명
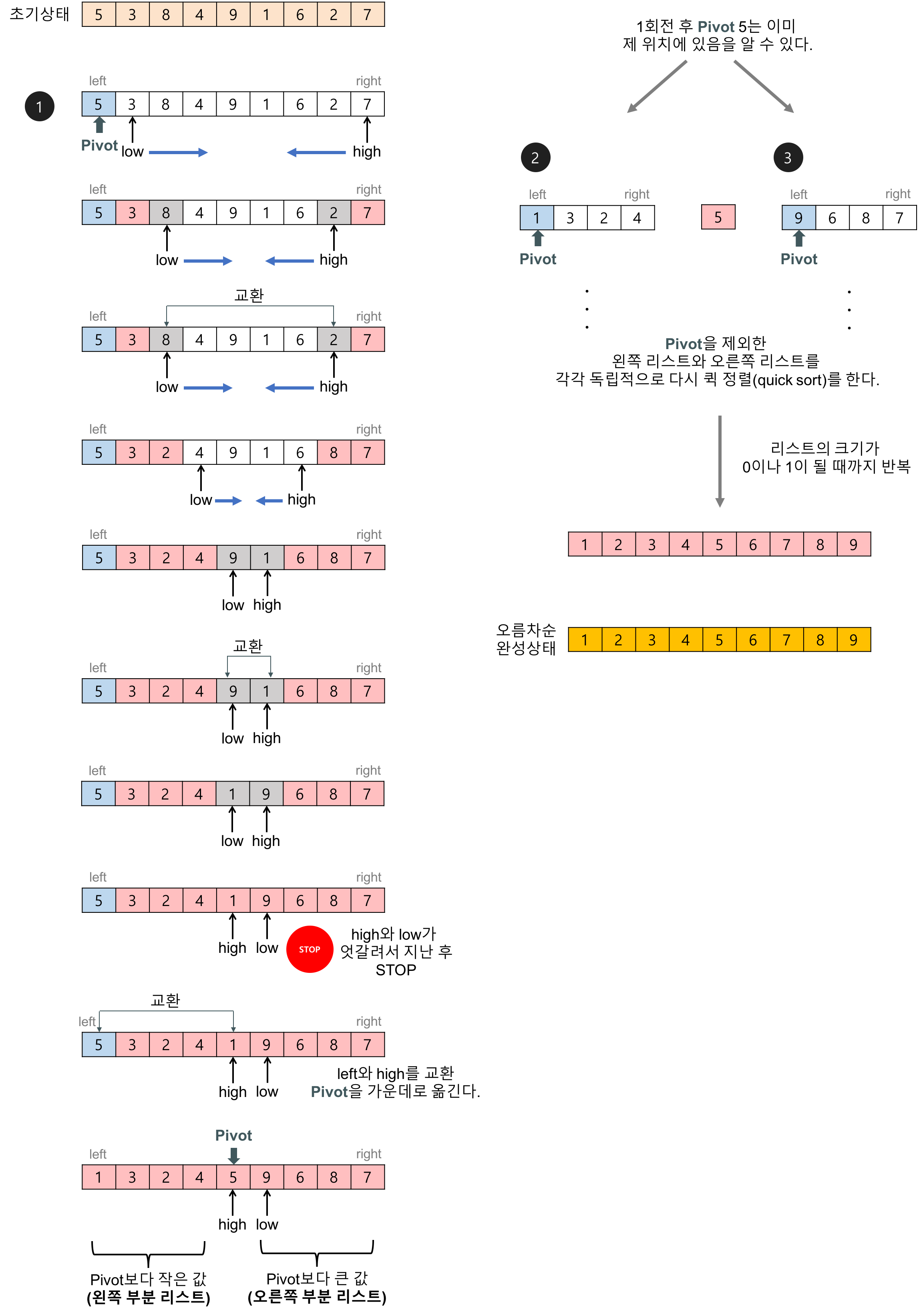
예를 들어 다음과 같은 데이터가 있다고 가정한다.
[6, 5, 1, 4, 7, 2, 3]이때 4라는 피벗값(기준)을 설정하여 피벗 값 기준으로 왼쪽으로는 (피벗보다) 작은 값, 오른쪽으로는 (피벗보다) 큰 값을 위치시킨다.
p
[3, 2, 1] < 4 < [7, 5, 6]이후 왼쪽에 있는 데이터는 더이상 오른쪽에 위치한 데이터와 비교가 불필요하므로 해당 데이터만 대상으로 다시 퀵정렬을 수행한다. 2를 피벗으로 두었을 때, 정렬이 완료된 상태이기 때문에 더 이상 정렬 작업을 수행하지 않는다.
p
[1] < 2 < [3]오른쪽 데이터도 마찬가지로 정렬을 수행한다. 우선 5값을 피벗으로 두었을 때는, 오른편으로 두개의 데이터가 쏠리므로 5피벗은 가만히 둔채로 오른쪽 데이터에 퀵정렬을 다시 수행하지 않는다.
1) 퀵정렬 수행
p
[] < 5 < [7, 6]2) 오른쪽 [7,6]에 대한 퀵정렬 추가 수행.
p
[6] < 7 < []퀵 정렬의 특징
- 원소 개수가 나빠질수록 나쁜 중간값(피벗 값)을 선택할 가능성이 높아지기 때문에, 원소 개수에 따라서 퀵정렬을 선택하든지 다른 정렬과 '혼합'해서 사용하던지 선택할 수 있음.
- 이상적인 시간복잡도는 O(NlogN) 이지만, 최악의 경우에는 O(N^2)의 시간 복잡도를 가질 수도 있음.
- 최악의 경우, 한편으로만 데이터가 몰리는 경우에는 이것을 방지하기 위해서 피벗값을 '잘' 골라내야하는 데, LIST의 첫번째, 중앙값, 마지막 값 중에 크기가 중간이 값을 사용하는 방법이 자주 사용됨.
파이썬 구현
퀵정렬부터는 '재귀 함수' 방법으로 사용될 수 있음.
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
lesser_arr, equal_arr, greater_arr = [], [], []
for num in arr:
if num < pivot:
lesser_arr.append(num)
elif num > pivot:
greater_arr.append(num)
else:
equal_arr.append(num)
return quick_sort(lesser_arr) + equal_arr + quick_sort(greater_arr)[최적화]
매번 재귀 호출될 때마다 리스트를 생성하여야 하기 때문에, 메모리에 대한 비효율성이 발견됨. 만약 큰사이즈의 입력 LIST를 받게 된다면 이러한 단점이 문제가 될 수 있기 때문에, in-place 정렬이 선호된다.
- quick_sort()는 크게 sort()와 partition() 2개의 내부 함수로 나누어짐.
- sort() 함수는 재귀 함수이며 정렬 범위를 시작 인덱스와 끝 인덱스로 인자로 입력받음.
- partition 단계에서는 피벗 기준으로 최대한 왼쪽, 오른쪽 값들이 정리될 수 있도록 함수를 작성한다.
def quick_sort(arr):
def sort(low, high):
if high <= low:
return
mid = partition(low, high)
sort(low, mid - 1)
sort(mid, high)
def partition(low, high):
pivot = arr[(low + high) // 2]
while low <= high:
while arr[low] < pivot:
low += 1
while arr[high] > pivot:
high -= 1
if low <= high:
arr[low], arr[high] = arr[high], arr[low]
low, high = low + 1, high - 1
return low
return sort(0, len(arr) - 1)위 partition단계를 1번 그림으로 잘 설명하였다.
반응형
'알고리즘' 카테고리의 다른 글
| [알고리즘] BFS (너비 우선 탐색) / DFS (깊이 우선 탐색) (0) | 2022.07.02 |
|---|---|
| [알고리즘] 5) 병합 정렬 알고리즘 (0) | 2022.06.26 |
| [알고리즘] 3) 삽입 정렬 알고리즘 (0) | 2022.06.26 |
| [알고리즘] 2) 버블 정렬 알고리즘 (0) | 2022.06.26 |
| [알고리즘] 1) 선택 정렬 알고리즘 (0) | 2022.06.26 |
'알고리즘' Related Articles
more


Comments